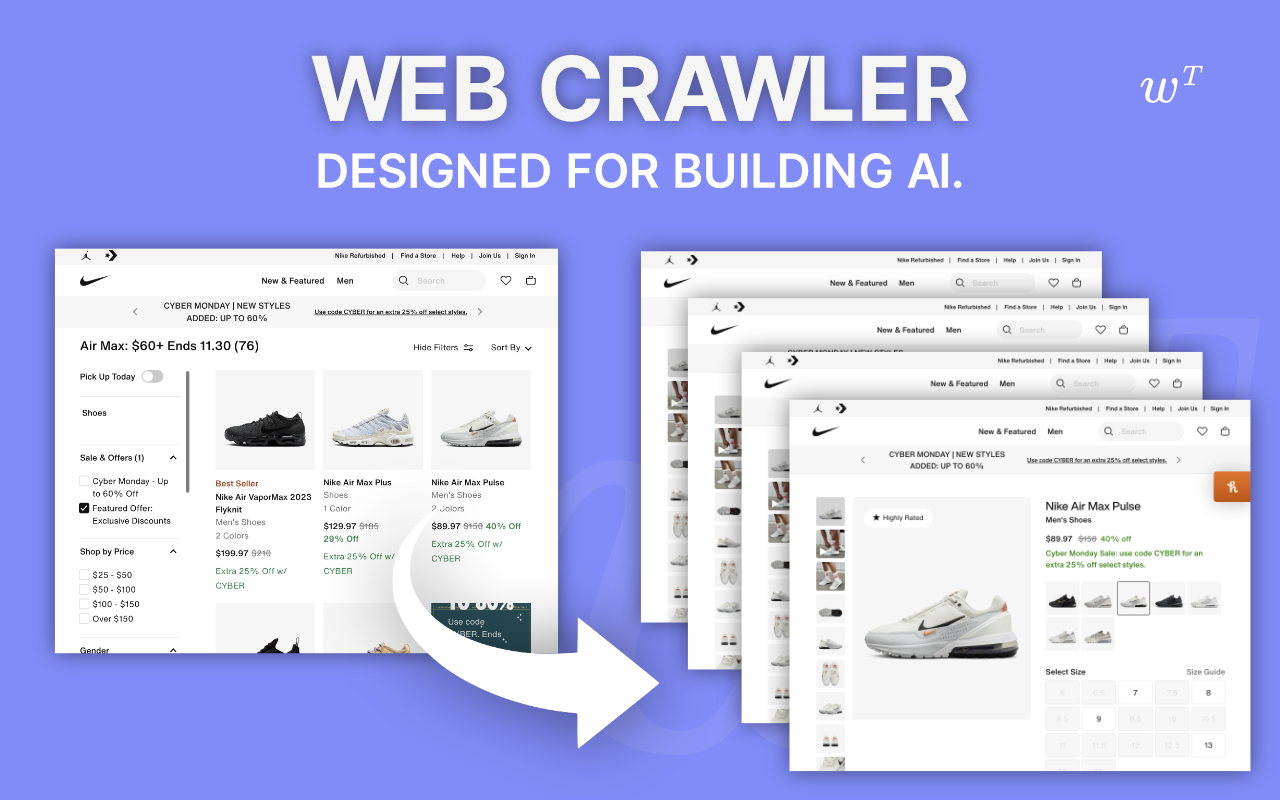
Crawl
Download entire websites for your LLMs.
Give us any home page and we extract all the pages and PDFs as text for you.
Extract PDFs
Runs on Cloud
Self Service
No Credit Card Required.
Only 1 Line of Code
Or use our visual interface.
Crawl a websiteCrawl an entire website and download the data
import webtranpsose as webt
crawl = webt.Crawl(
'https://www.paulgraham.com',
max_pages=300,
render_js=False,
)
crawl = await crawl.crawl()
crawl.download()
Customized Web CrawlCrawl a website with custom parameters
import webtranpsose as webt
crawl = webt.Crawl(
'https://www.paulgraham.com',
allowed_urls=['https://www.paulgraham.com/articles/*'],
banned_urls=['https://www.paulgraham.com/lisp-love-songs/*'],
)
crawl = await crawl.crawl()
crawl.download()